使用k-means分群的幾個缺點
k-means是依據資料點彼此之間的距離來進行分群的,與群心越接近的資料點越會被分成同一群。但有時候資料的分群不能光看距離的,以下分別舉分個例子。
例子A: 各群的的大小不同
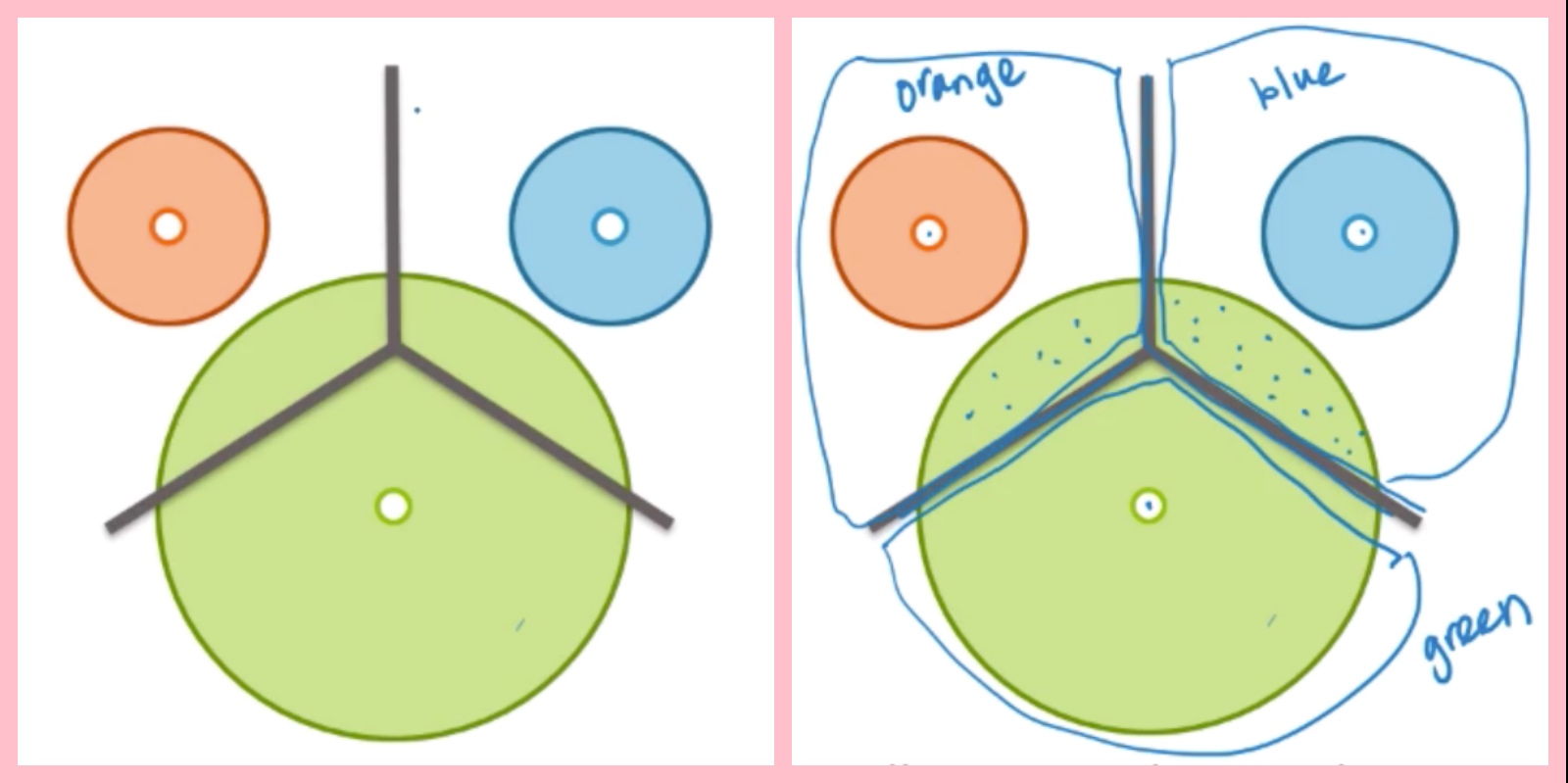
如上圖左側所示,橘、藍、綠三個群體的大小並不相同,可是如果依照距離來做分群的話,就會依照中間的三條線(Benz’ logo?)來切出三個群。從右側的圖顯然可以發現,原本屬於綠色的資料點會被錯誤分群到橘、藍兩群。
例子B: 群與群之間有重疊
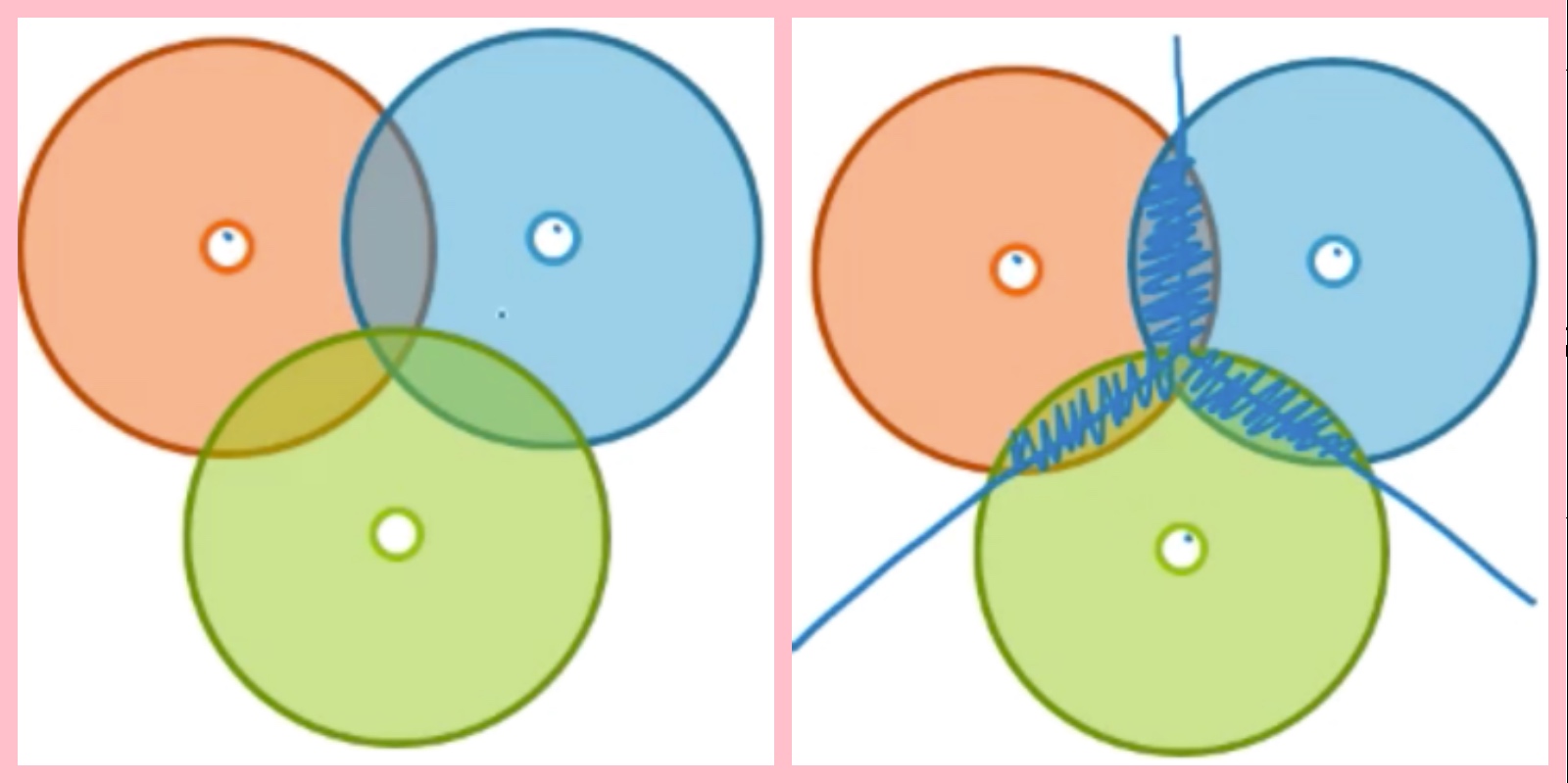
第二個例子是重疊,如上圖左側可見,三個群體是有互相重疊(overlapping)的情況發生,我們很難判斷位於重疊區域的資料點應該會被分到哪一個群當中。可是如使用k-means做分群,那重疊的區域就會被強制分到一個群體當中(上圖右側),可能會有錯誤分群的情況發生。
例子C: 各群的形狀不同
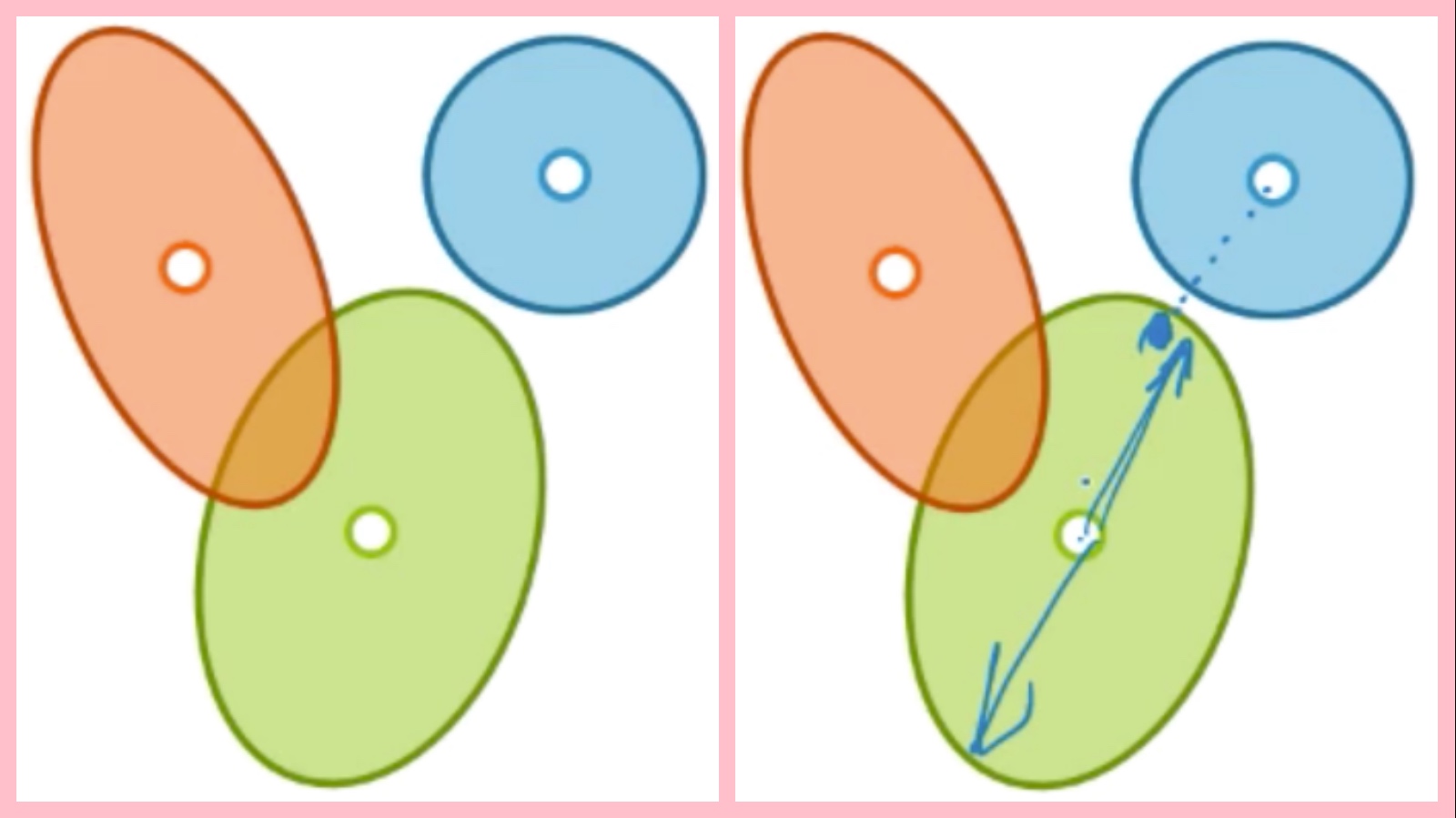
最後一種情況就是群的形狀並非都是一致的,有些群體可以是橢圓(二維空間為例),而且橢圓的形狀也不一致,如上圖左側。但因為k-means的分群是依照距離來計算相似度,所以會有錯誤的情狀。如上圖右側的點,他應該被分為綠色的群,可是因為距離藍色的群心比較接近,所以會被錯誤的分成藍色的群。